Welcome to the Apache UIMA™ project. Our goal is to support a thriving community of users and
developers of UIMA frameworks, tools, and annotators,
facilitating the analysis of unstructured content such as text, audio and
video.
What is UIMA?
Unstructured Information Management applications are
software systems that analyze large volumes of
unstructured information in order to discover knowledge
that is relevant to an end user. An example UIM
application might ingest plain text and identify
entities, such as persons, places, organizations; or
relations, such as works-for or located-at.
UIMA enables applications to be decomposed into components,
for example "language identification" => "language
specific segmentation" => "sentence boundary
detection" => "entity detection (person/place names
etc.)". Each component implements interfaces defined
by the framework and provides self-describing
metadata via XML descriptor files. The framework manages
these components and the data flow between them.
Components are written in Java or C++; the data that
flows between components is designed for efficient
mapping between these languages.
UIMA additionally
provides capabilities to wrap components as network
services, and can scale to very large volumes by
replicating processing pipelines over a cluster of
networked nodes.
Apache UIMA is an Apache-licensed open source
implementation of the
UIMA specification [pdf]
[doc] (that
specification is, in turn, being developed concurrently
by a technical committee within
OASIS
, a standards organization). We invite and encourage you
to participate in both the implementation and
specification efforts.
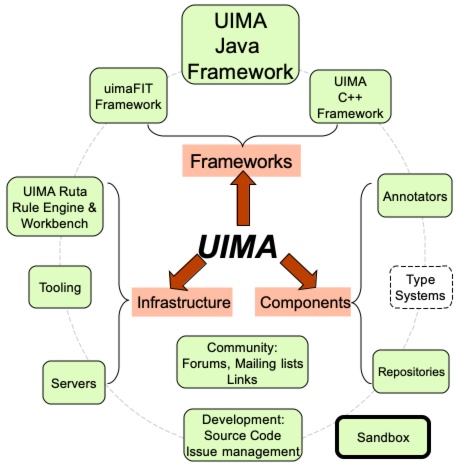
Here you can find:
- Frameworks
- Components, and
- Infrastructure,
all licensed under the Apache license. The dashed-line boxes
above are placeholders for possible future additions.
The Frameworks run the components, and are available for both Java and
C++. The
Java Framework supports running both Java and non-Java
components (using the C++ framework). The
C++ framework, besides
supporting annotators written in C/C++, also supports Perl, Python, and
TCL annotators.
The frameworks support configuring and running pipelines of
Annotator components. These components do the actual work
of analyzing the unstructured information. Users can write
their own annotators, or configure and use pre-existing
annotators. Some annotators are available as part of this project;
others are contained in various repositories on the internet.
GitHub.com lists over
900 repositories that have dependencies on
the UIMA Java SDK core.
In 2018, the internals of the UIMA Java framework were redesigned for a tighter integration with Java
including for example,
Java Streams
support for working with annotations, and for
supporting higher performance on modern processors with memory caches. This is available as Version 3.x.x
of the UIMA Java SDK, and associated components. Version 2 continues to be supported, but new work should
use version 3.
An extensive rule-based scripting language
(RUTA), an associated analysis engine built on top of UIMA, and an Eclipse-based tooling workbench for interactively
developing and testing the rules, is part of this project.
Additional infrastructure support components include a simple
server that can receive REST requests and return annotation results,
for use by other web services.
The Addons and Sandbox is for Addons (Annotators and other things) for UIMA, and
a place where new ideas are developed for potential incorporation into the project.


 Welcome to the Apache UIMA project
Welcome to the Apache UIMA project